Containers, Docker, Kubernetes -- it's a lot to keep track of. Are you looking for a primer on what all this containerization technology is all about, what it means, and how you can make use of it?
At a high level, they're a lightweight way to package everything your app needs to run -- the code, any libraries, and any necessary runtimes. This means you can make sure your app runs the same everywhere.
One common sentiment in the data science community is that they don't need containers. And I have definitely tried to ignore that space for quite a while. But containers are just a really useful thing to learn, even for those doing machine learning. Containers can be useful for all sorts of industries. By standardizing how applications are packaged, it makes life better for everyone. And that sounds super useful in the general software context. But one of the things I struggled with when I first encountered containers was that machine learning workflows called for a slightly different approach when it comes to software and how code is both used and run. I've been pretty pleased with how useful containers have been, even though they were not necessarily designed specifically for data scientists and machine learning engineers.
For one thing, it brings a consistent running environment. Your app runs the same on your laptop, in QA or staging, and in production. And in machine learning, we often have different data sets for experimenting, training, evaluation, and test. Add to that the various configurations for models, as well as any relevant metadata that also needs to be passed in, and it's not hard to see why having easily configured environments can really improve productivity and, importantly, reduce mistakes.
Another nice thing about containers, which just doesn't get talked about nearly enough, is consistency across team members. We used to follow step-by-step instructions to configure our machines and basically hope that that meant we were all working in the same computer environment. Unfortunately, instructions change over time and get stale, which leads to inconsistencies between team members and subtle bugs that are really tricky to iron out.
A final aspect of containers, which is just fabulous, is self-documenting runtime requirements. Instead of handing over an app and saying, run this, you can define exactly what the system should be, analogous to a package.json in JavaScript, or a requirements.txt in Python, but at the system level.
Oftentimes when projects are open source, the README will ask users to download the app code and then give them instructions for installing language binaries, libraries, and other dependencies. Now you can just run it as a Docker image. For example, if you were writing a Node.js REST API, you could actually run it without even installing Node.js on your workstation.  And containers, I think, could also make reproducible papers and results much easier. I also saw that Compute Engine also lets you choose a container image that can be directly run when creating a virtual machine.
And containers, I think, could also make reproducible papers and results much easier. I also saw that Compute Engine also lets you choose a container image that can be directly run when creating a virtual machine.
But if you're planning to load a container into a VM directly like that, why not just use the virtual machine? You could just create a custom virtual machine image. Yeah, but there's a couple of drawbacks that give containers an edge here. Since VM images are literally a snapshot of the disk, they tend to be huge and opaque as to both what's inside and how it got to that state.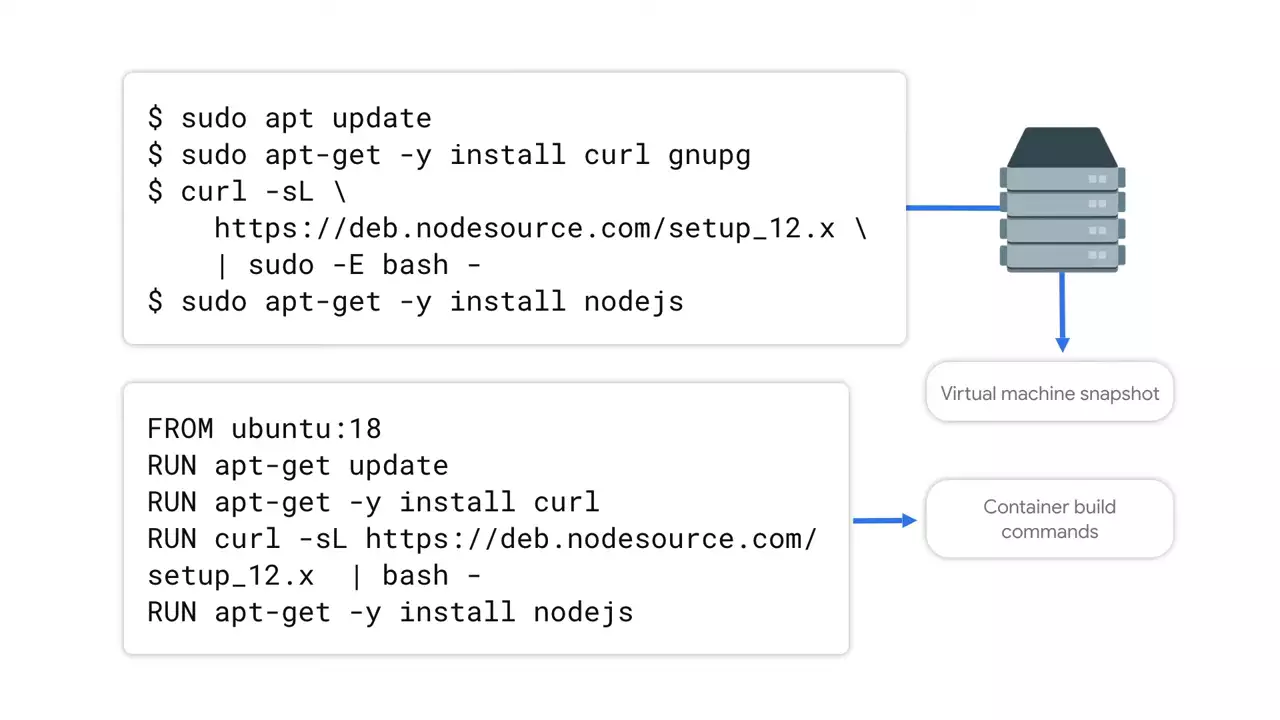
On the other hand, Docker images are not actually a snapshot of whatever happens to be on disk, but rather they're fully defined by their Docker files. So then they not only have a much more compact representation that's universally usable. They're also human-readable.
Where I see containers with a clear advantage is when doing this at scale -- say, for distributed training. Deploy to multiple machines, environments, and scale up and down. Containers can start almost instantly, and VM images, they take a lot longer to do these types of tasks.
So let's say you believe us that containers are useful. The next step, then, is to understand how a container is put together, how to run one, and what is going on inside.
First, let's define what goes into our container. That starts with a Docker file. This defines every step that needs to happen to install dependencies, build and configure your app, and actually run your app.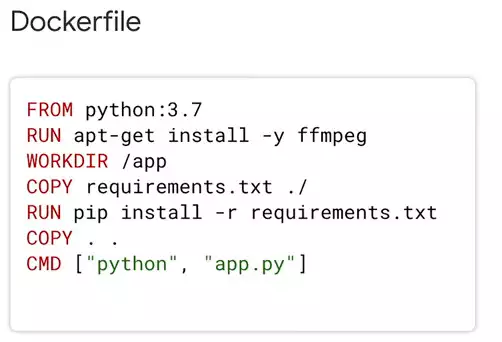 It all starts from a base image. And what's great about Docker files being an industry standard is that there are official base images. So you could, for example, use an official Python image as your base, and it already has an operating system and a version of Python installed. After that, you can put all sorts of stuff into it, from library installation commands to downloading files from your storage buckets, to copying out a portion of your source code and relevant dependencies.
It all starts from a base image. And what's great about Docker files being an industry standard is that there are official base images. So you could, for example, use an official Python image as your base, and it already has an operating system and a version of Python installed. After that, you can put all sorts of stuff into it, from library installation commands to downloading files from your storage buckets, to copying out a portion of your source code and relevant dependencies.
So from there, the Docker file is then built into a container image. You can do the build either on your own machine, in the cloud using a tool like Cloud Build, or as part of your own CI/CD pipeline. 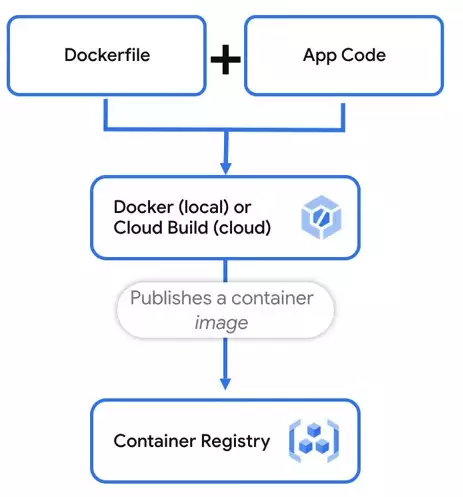 The image is built by reading the Docker file and performing each step listed. After the build is complete, you want to publish your image to a container registry, which can be either public or private. When it's time for your app to actually start running, the container image is where the image will be pulled from before it starts going.
The image is built by reading the Docker file and performing each step listed. After the build is complete, you want to publish your image to a container registry, which can be either public or private. When it's time for your app to actually start running, the container image is where the image will be pulled from before it starts going.
Once you have a container image ready to go, you can run it in all sorts of environments. You can run it on your computer, or you can run it in a Kubernetes cluster, or in a managed service like Cloud Run. There's also some open source projects, which try to make it easy to run containers for machine learning on Kubernetes-- for example, Kubeflow.
It's so great to see all of these tools take on and use containers in the ecosystem. But how big can just any old container really get? As big as you can imagine

No comments yet