Serverless Architecture Explained
Serverless computing... is a lie! Seriously though, it isn't a real thing. It's just the name that's a bit misleading. In this article I'm going to explain what serverless architecture is, and how it can save you time and money.
So how can you run applications without any servers? You can't. Prepare yourself for this. Serverless infrastructure runs on... servers. It's not magic. It's not powered by fairy dust. It runs on servers, just like everything else. It's called "serverless", not because there aren't any servers involved; but because you don't need to know anything about them.
Serverless is a way of building applications from cloud-native components. I'm going to give you an example of how that can be done later in this article, and then we can look at the pros and cons, but first let's try and position serverless computing amongst the rest of our cloud services.
When it comes to cloud, there are a bazillion "as a service" acronyms floating around; but in general, cloud services can be broken down into these three.
- Infrastructure as a Service (IaaS)
- Platform as a Service (PaaS)
- Software as a Service (SaaS)
As you move from top to bottom, you increase the degree of abstraction - meaning you've outsourced more responsibility for the underlying infrastructure components. That means there's less for you to worry about, but the flip-side is you lose some control. The degree of control you get moves in the opposite direction - increasing from bottom to top. With Infrastructure as a Service you're responsible for pretty much everything, bar the hardware. You manage the operating system, the full server and software stack, and the application itself; and you can tweak each of them as required. On the other end of the scale, with Software as a Service you pay your money and you get the service. You don't need to worry about how it works, but it does what it does, and there's not a lot of opportunity to change how it behaves.
So where does serverless fit on this scale? Serverless lands somewhere between PaaS and SaaS. I consider it a type of Platform as a Service, but towards a higher abstraction end of Platform as a Service.
Serverless sometimes gets designated the name "Function as a Service", but there are enough "as a service" acronyms already, and some of the products currently marketed as serverless were already being marketed as Platform as a Service before that became a trendy name.
The line between serverless architecture and traditional Platform as a Service lies in how your application is composed. Applications composed using traditional Platform as a Service are constructed in much the same way as with full servers. You just mask off a chunk of the underlying infrastructure complexity, and make it someone else's problem.
Applications composed using a serverless approach need to be designed a little differently. Essentially, they are broken down into single-purpose autonomous functions. You have no control over where these functions get executed, so they have to be self-contained and assume no persistent application state. This is different from traditional Platform as a Service, where although you might not have visibility of the underlying server you at least know of its existence; and you know your code is running on a server that is going to persist between executions.
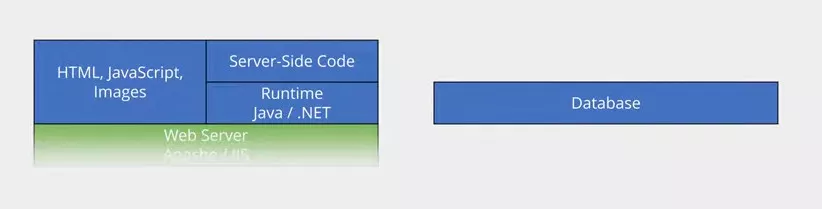
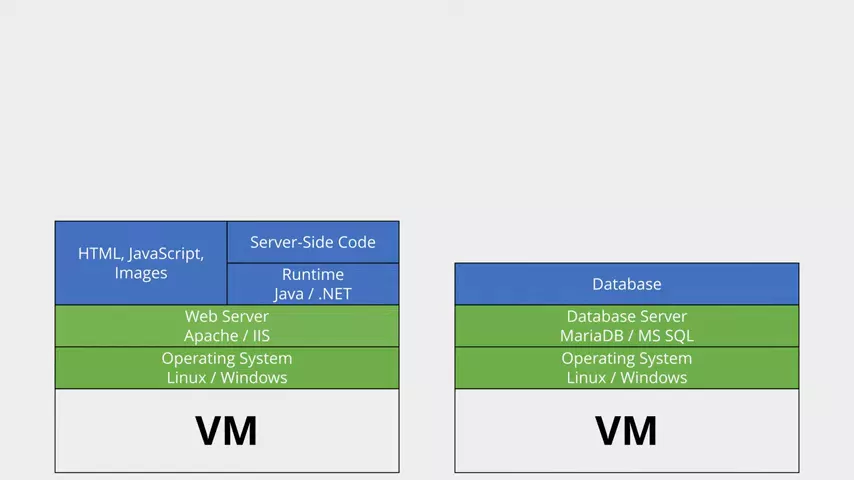
The best way to explain this is with an example. Let's imagine a simple web app where we've got a text field, and as we type into it the page content dynamically updates. Think of something like the search bar on YouTube that presents you with updated suggestions as you type. Here's a representation of the different layers that might be involved in a traditional server infrastructure.
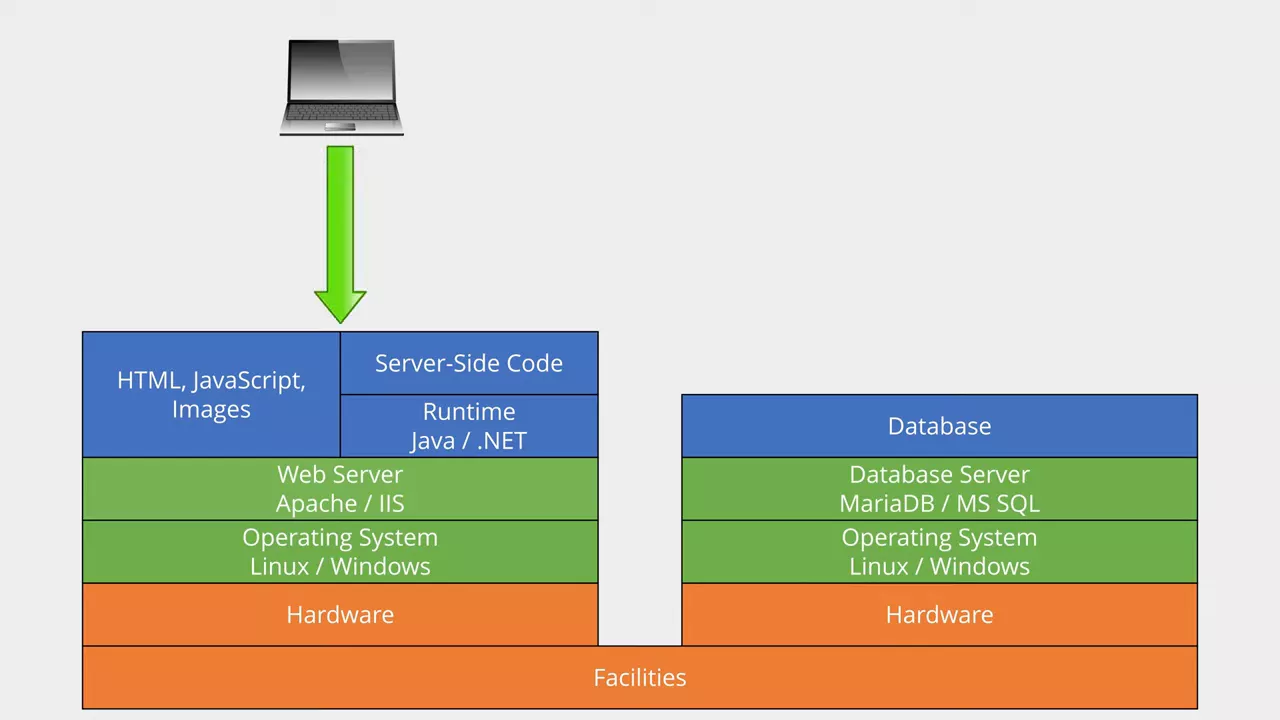
At the bottom we have the physical facilities, followed by the actual hardware. On top of that we have an operating system like Linux or Windows. On top of that we have the web server software like Apache or IIS. That web server can serve static content like HTML, JavaScript and images; but it can also serve dynamic content, generated on the fly using server-side code that uses a runtime environment like Java or the .NET Framework. We've also got a database server running something like MariaDB or Microsoft SQL server, which hosts a database full of our data.
In our example, the client initially sends a request for a web page and receives static content comprised of our page with its text field, and some client-side JavaScript that runs when the text field gets updated. This JavaScript fires off some AJAX calls to request additional content from the server as the field's value changes. The content is generated by the server-side code, which queries the contents of our database. As far as web apps go, that's fairly basic stuff.
Now let's convert this to a cloud-hosted equivalent, using Infrastructure as a Service. All of the physical nuts and bolts become someone else's problem, and we just have to deal with the operating system and everything else above it inside managed virtual machines.
Taking this a step further, let's move to Platform as a Service. AWS and Azure are the two biggest players here, and both have the ability to host managed database instances where the underlying server is abstracted away. So that's our data component taken care of. Both of these platforms also allow for the web server to be hosted as a managed entity, where you get a bit of control, but a lot is hidden from you.
You primarily manage the code and the data, and the vendor manages most of everything else. In Azure this would be done using an App Service, and in AWS you'd use an Elastic Beanstalk; because whoever names Amazon's AWS products is clearly on some pretty exotic drugs!
While this abstracts away a lot the underlying complexity, it doesn't remove all of it. You still need to choose an underlying web server. You still need to design for scalability and resilience. AWS and Azure can automate scaling up and scaling down, but you need to define how and when to do this, and design your application to support it. Even though you can't get access to it, there is still a web server hosting your app, and you need to pay for its resources that it's consuming over time... whether or not it's actually doing anything useful with them.
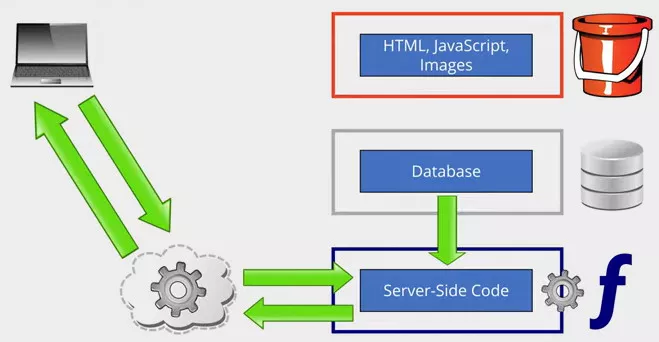
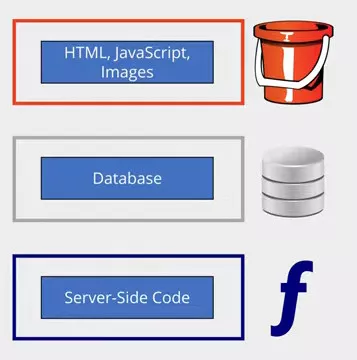
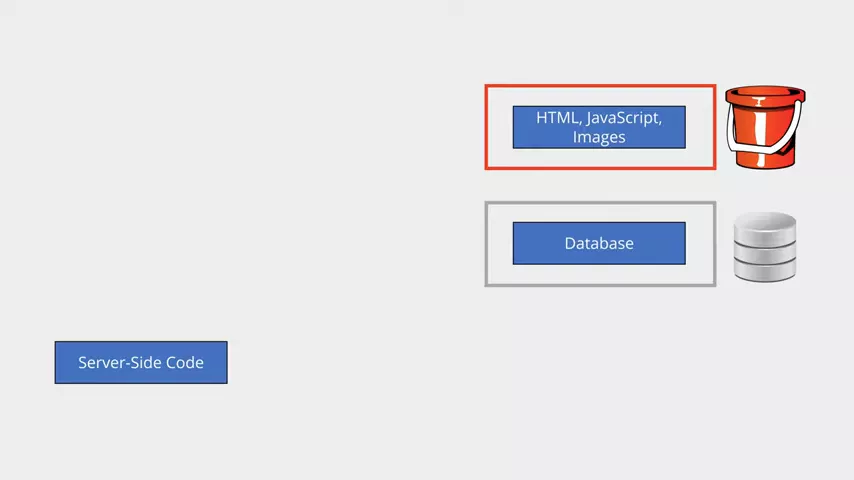
Let's take a look at how the app can be converted to a serverless architecture. Let's get rid of the infrastructure and implementation detail, leaving just our application itself - our code and our data.
Starting with the static content first, we can stick that into cloud storage - an Azure Storage Account or AWS S3 Bucket. Both vendors support serving files directly from storage as static websites. This is very simplistic, and can't run any code. With this option enabled, if you browse to an HTML file it will return it as a web page instead of as a download. Same for JavaScript or images. It's not going to process any PHP for you, though. You'd need a proper web server for that. You could use this to host a very basic website without having to configure a web server anywhere. AWS or Azure take care of it for you through their storage services. You're not having to pay for a web server either. Accessing the static content this way is just classed as regular storage access; so you pay for the data storage and the transfer, but you don't have to pay any standing charge for a web server. This won't work for our example, as we need to generate dynamic content; but it solves part of the problem, and could be used to serve up a page containing the text field and the client-side JavaScript.
To provide the rest of our app's functionality we need somewhere to run our code. We can do this using a Function in azure or Lambda Function in AWS.
Same thing, different vendor. These functions aren't connected to a website - they're just somewhere to execute code when triggered. Where this code gets executed is the vendor's problem to solve.
How this works in practice is you will typically get billed for the execution time while your code is processing, rather than paying a standing charge to keep a server running. Just like with static content served from cloud storage, you're only paying while it's actually in use. That's all well and good, but having code executing in an isolated bubble is of no use to us if we can't hook it up to our website. To do this we can use Amazon's API Gateway or Azure API Management.
This receives AJAX calls from the client-side JavaScript you served up as static content, and triggers our functions to execute the necessary code. The function code interacts with our database, and passes results back to the API. The API returns the results in a web response to the client-side JavaScript, which updates the page. So now we have a fully functioning web app, and nowhere have we had to configure any servers. There are servers hosting all of this under the covers, of course; but we've not had to configure or manage any of it, and we're not paying any standing charges for them. That's not to say it's free. Don't worry. Amazon and Microsoft will get your money, but the pricing model is quite different.
With Infrastructure as a Service or Platform as a Service you're paying to keep the server running all the while you want your app to be available. With serverless you're only paying when it's actually in use. It's always available, but it's only when someone starts interacting with it that you incur costs. This can be advantageous, by correlating running costs directly to the benefits you derive from it; although the flip side is it can make your costs more unpredictable as a result.
Another benefit of serverless is that it allows developers to deploy their apps directly to the cloud, without having to rely too much on infrastructure people; who tend to ask annoying questions like "How many people will be using this app", "Where are they based?", and "What resilience do you need?". You know... the kind of boring questions that developers don't always want to concern themselves with. Those questions are still important, by the way. Just because you can deploy it without giving thought to it, doesn't mean you should. Certainly, once it's been deployed *properly*, there's a lot less maintenance for your infrastructure team to worry about with serverless architecture. Especially as serverless architecture is very easy to scale. Because you have to break your apps down into decoupled components in order to use serverless architecture, most of them will simply scale automatically. More users requesting content? Amazon's global S3 service takes care of that. More calls to code in functions? Azure spins up more resources to process them. Their problem. Not yours.
Read also: Is the Cloud Secure Enough?
There are some disadvantages though. While serverless architecture can be a major cost-saving for low-usage apps, because you're not being charged when they're idle; the other side of that coin is that a very heavily utilized app can rack up costs pretty quickly. Debugging can also be an issue. A lot of these components are being handled by a proprietary third party service. If you're trying to get the bottom of an issue, it's not like you can just spin up a replica environment on your laptop.
Finally, and perhaps most significantly: there is a high degree of vendor lock-in. If you build an application using Amazon's serverless cloud components, your application is completely reliant on Amazon's cloud. You can't easily pick it up and run it somewhere else as you could with a more traditionally deployed app. This introduces some risks for you to consider. What does it mean if Microsoft decides to double the price of Function execution time? Your costs go up. Significantly. What if Amazon decides they no longer want to support Java in their Lambda Functions, and that's what you were using? Well, now you need to rewrite your code or your app will stop working. This sort of thing does happen: PowerApps anyone?
I suggest that it would be prudent to make an exit plan when you make a significant investment in serverless. In other words, have a plan for how you'll transition your apps away should it at some point in the future cease to be viable. By doing this you will have quantified and managed the risk; so if your chosen vendor does suddenly drop you in it, you've got a Plan B ready to go. This can avoid a whole lot of panicked re-engineering and spiraling costs. The best way to learn more about serverless computing is to have a play with it.