In this case study, we will delve into the intricacies of creating a video recommendation system, specifically tailored for YouTube users. The primary goal of this system is to enhance user engagement by providing personalized video suggestions while also introducing users to new and diverse content. To achieve this, we will discuss the problem statement and the metrics designed to evaluate the system's performance.
1. Problem Statement:
The challenge at hand is to construct a robust video recommendation system that optimizes user engagement on the YouTube platform. This entails the following objectives:
- Maximizing User Engagement: The system should prioritize recommendations that keep users engaged with the platform for longer periods.
- Diversifying Content: Recommending not only popular videos but also introducing users to new types of content they might find interesting.

2. Metrics Design and Requirements:
To gauge the effectiveness of our video recommendation system, we have established a set of metrics and requirements that encompass both offline and online evaluation aspects.
Metrics:
Offline Metrics:
To assess the quality of recommendations generated by our model, we will utilize the following metrics:
- Precision: Measuring the accuracy of recommended videos that users actually engage with.
- Recall: Evaluating the system's ability to suggest relevant videos, ensuring we do not miss potential matches.
- Ranking Loss: Assessing the order in which videos are presented in the recommendation list.
- Log Loss: Calculating the log-likelihood of observed user interactions with recommended videos.
Online Metrics:
To evaluate the system's real-world impact, we will employ A/B testing, focusing on the following metrics:
- Click Through Rates (CTR): Measuring the percentage of users who click on recommended videos.
- Watch Time: Determining the total time users spend watching recommended content.
- Conversion Rates: Evaluating the effectiveness of video recommendations in converting users into engaged viewers.
Requirements:-
Training:
Given the unpredictability of user behavior and the potential for videos to become viral at any time, our training process should be adaptable and frequent. We aim for:
- High Throughput: The ability to process large volumes of data efficiently.
- Frequent Retraining: The capability to retrain the model multiple times throughout the day to capture temporal changes in user preferences.
Inference:
When serving recommendations to users visiting the homepage, we must meet stringent latency requirements:
- Latency: Response times should ideally be under 100ms but must not exceed 200ms.
Balancing Exploration vs. Exploitation:
To ensure a balance between relevance and freshness in our recommendations, we need to find the right equilibrium between exploiting historical user data and exposing users to new content.
In summary, our video recommendation system aims to achieve the following goals:
- Metrics: Strive for reasonable precision while maintaining a high recall rate in our recommendations.
- Training: Prioritize high throughput and the ability to retrain the model frequently throughout the day to adapt to changing user behaviors.
- Inference: Achieve low latency, ideally below 100ms and not exceeding 200ms when recommending 100 videos to users.
- Balance Exploration vs. Exploitation: Find the optimal trade-off between recommending relevant content based on historical data and introducing users to fresh, new content.
By addressing these objectives, our video recommendation system aims to enhance user satisfaction and engagement on the YouTube platform, ultimately leading to a more fulfilling user experience.
3. Multi-stage models:
let's dive deeper into each of these stages and explore their key components.
Candidate Generation Model:
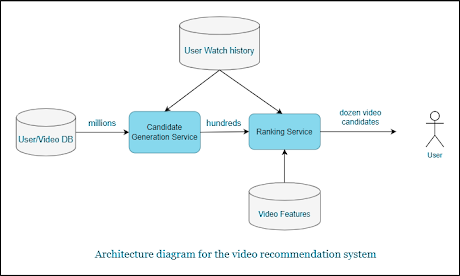
Feature Engineering:
Feature engineering is a critical aspect of building an effective candidate generation model. It involves representing users and videos in a way that captures their preferences and characteristics. Some essential features for this stage include:
- Watched Video IDs: A list of videos the user has previously watched.
- Video Embedding: Embeddings that represent the content of each video, allowing the model to understand their content similarity.
- Historical Search Queries: Past search queries made by the user, which can provide insights into their interests.
- Text Embedding: Embeddings for text data associated with videos, such as titles, descriptions, and tags.
- Location and Geolocation Embedding: Information about the user's location, which can impact their video preferences.
- User Associated Features: User-specific attributes like age and gender that can help personalize recommendations.
- Normalization or Standardization: Scaling features to ensure consistent input for the model.
- Previous Impression: Information on whether the user interacted positively with previous recommendations.
- Time-Related Features: Temporal features like the month, week_of_year, holidays, day_of_week, and hour_of_day, which capture time-dependent preferences.
Training Data:
To train the candidate generation model, you'll need a suitable dataset. This dataset can be constructed from user-watched history data, where the majority of interactions involve not watching a video (typically around 2% watched vs. 98% not-watched). This data helps the model learn patterns associated with user preferences.
Model:
Matrix factorization is a common approach for candidate generation, as it efficiently captures user-video interactions. Collaborative filtering algorithms, like Singular Value Decomposition (SVD) or Alternating Least Squares (ALS), can be employed for this purpose. However, for large-scale systems like those at Facebook and Google, alternative methods with lower latency, such as Inverted Index, FAISS, or Google ScaNN, are preferred for generating candidate lists.
Ranking Model:
The ranking model plays a crucial role in determining the order in which video candidates are presented to users. Here are some key considerations for the ranking model:
Feature Engineering:
Similar to the candidate generation stage, the ranking model requires well-crafted features to make informed decisions. These features can include:
- Watched Video IDs: A list of videos in the candidate set.
- Video Embedding: Embeddings representing candidate videos.
- Historical Search Query: Previous search queries that might influence ranking.
- Text Embedding: Embeddings of video titles, descriptions, and other textual data.
- Location and Geolocation Embedding: Location-related features for personalization.
- User Associated Features: User attributes like age and gender.
- Normalization or Standardization: Ensuring consistent feature scales.
- Previous Impression: User interactions with previous recommendations.
- Time-Related Features: Temporal features capturing time-dependent preferences.
Training Data:
Training data for the ranking model can be constructed using user interactions with recommended videos. This data helps the model learn to estimate the probability of a user watching a video. The ratio of watched to not-watched videos is typically highly imbalanced, with the majority being not-watched.
Model:
Starting with a simple model is often a good practice and allows for gradual complexity if necessary. A fully connected neural network with sigmoid activation at the last layer is a straightforward yet powerful choice for representing non-linear relationships and estimating probabilities within the [0, 1] range. The use of Rectified Linear Unit (ReLU) activation for hidden layers is effective in practice.
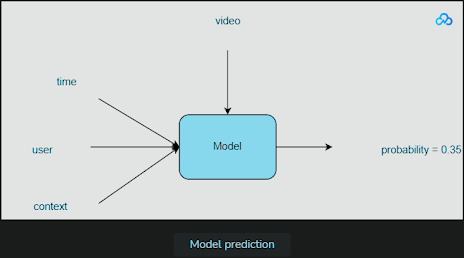
The loss function can be cross-entropy loss, which aligns with the goal of estimating probabilities.
Continuation of Building a Video Recommendation System: Calculation, Estimation, and System Design
4. Calculation & Estimation:
In this section, we'll make several assumptions and calculations to estimate the scale and requirements of our video recommendation system.
Assumptions:
To simplify our calculations, we'll make the following assumptions:
1. Video views per month: 150 billion.
2. 10% of videos watched are from recommendations, totaling 15 billion videos.
3. A user sees 100 video recommendations on the homepage.
4. On average, a user watches two videos out of 100 recommendations.
5. Recommendations not interacted with within 10 minutes are considered missed.
6. There are a total of 1.3 billion users.
Data Size:
For one month, we have collected 15 billion positive labels (watched videos) and 750 billion negative labels (unwatched videos). Assuming each data point has hundreds of features and takes 500 bytes to store, the total size of this data for one month is approximately 0.4 Petabytes (PB).
To save costs, we can implement data retention strategies and keep the last six months or one year of data in the data lake, archiving older data in cold storage.
Bandwidth:
Assuming we need to generate recommendation requests for 10 million users every second, with each request containing ranks for 1,000 to 10,000 videos, we need a robust and high-speed recommendation pipeline to handle this scale.
5. System Design:
High-Level System Design:
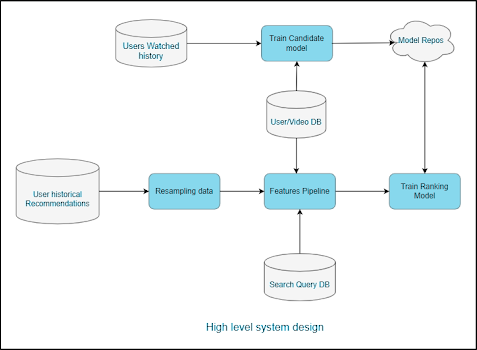
To address the challenges of building and scaling a video recommendation system, we need a well-structured system design. Here are some key components of the system:
- Database: This includes User Watched History, Search Query DB, User/Video DB, and User Historical Recommendations. These databases store user interactions, search history, user profiles, and video metadata.
- Resampling Data: This part of the pipeline is responsible for down-sampling negative samples, helping to balance the training process.
- Feature Pipeline: A pipeline program that generates all the required features for training a recommendation model. High throughput is crucial, especially for frequent model retraining. Tools like Spark, Elastic MapReduce, or Google DataProc can be used here.
- Model Repositories: Storage for all trained models, where AWS S3 is a popular choice. Real-time model updates can be facilitated by frequently pulling the latest models based on timestamps.
Challenges:
Several challenges need to be addressed in building a video recommendation system:
1. Huge Data Size: Given the massive amount of data generated, it's essential to manage and store data efficiently. One solution is to select a limited timeframe of recent data (e.g., one month or six months) for training and analysis.
2. Imbalanced Data: The ratio of watched to not-watched videos is highly imbalanced. To mitigate this, random negative down-sampling can be performed during training.
3. High Availability: Ensuring that the system is available and responsive is crucial. Solutions include deploying models as services in Docker containers and using Kubernetes to auto-scale the number of pods.
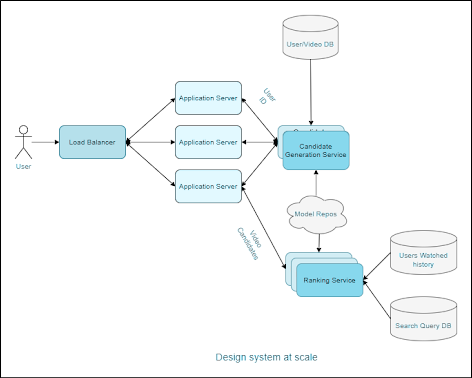
Flow of the System:
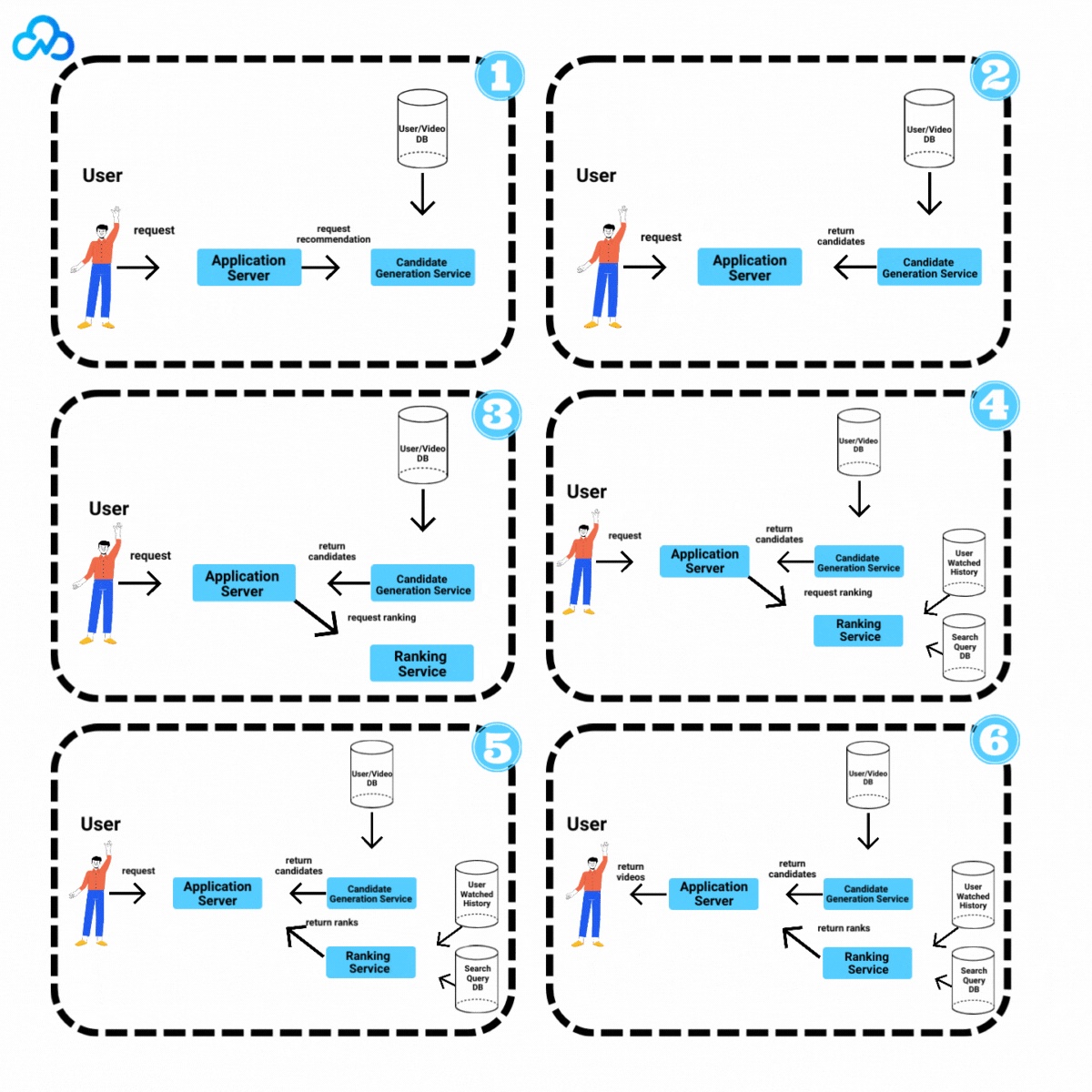
1. User sends a video recommendation request to the Application Server.
2. The Application Server requests video candidates from the Candidate Generation Model.
3. Upon receiving candidates, the Application Server passes the list to the Ranking Model for sorting based on watch probability.
4. The Ranking Model estimates watch probability and returns the sorted list to the Application Server.
5. The Application Server then presents the top-ranked videos to the user for viewing.
6. Scaling the Design:
To meet the demands of a large-scale system supporting 1.3 billion users, consider the following scaling strategies:
- Scale out (horizontal scaling) by deploying multiple Application Servers and using Load Balancers to distribute loads evenly.
- Similarly, scale out Candidate Generation Services and Ranking Services. Kubernetes Pods and the Kubernetes Pod Autoscaler can automate the scaling process.
- Implement Kube-proxy to allow the Candidate Generation Service to directly call the Ranking Service, reducing latency.
7. Follow-up Questions:
As you continue to develop and optimize your video recommendation system, several important questions may arise:
- Adapting to Changing User Behavior: Explore techniques like Multi-arm bandit algorithms, Bayesian Logistic Regression Models, and different loss functions to adjust to evolving user preferences and behavior.
- Handling Under-Explored Ranking Models: To address under-exploration, consider introducing randomization in the Ranking Service. For example, randomly assign 2% of requests to receive random candidates, while the remaining 98% receive sorted candidates from the Ranking Service. This can help discover hidden gems and improve recommendations.
In conclusion, building a video recommendation system at scale requires careful planning, infrastructure design, and continuous adaptation to user behavior. Scalability, data management, and system reliability are vital components of a successful recommendation system in the ever-evolving world of online video content.
For any it services, software development agency solutions visit our websites.

No comments yet