
Key value stores, which fall under the category of relational databases are well known for their simplicity and efficiency, in managing data. They are specifically designed to handle amounts of data and offer scalability through various operations and architectural principles. In this blog post we will delve into the operations involved in manipulating data in key value stores explore their architecture and discuss mechanisms that ensure high availability.
Operations for Data Access and Retrieval
In key value stores data manipulation revolves around a set of core operations:
1. GetItem: This operation retrieves the attributes of an item based on a given key. If the key does not exist it returns a result.
2. PutItem: Used to insert or replace an item within the store this operation creates an item when a new key is provided or replaces an existing item for a existing key.
3. UpdateItem: This operation allows for modifications to be made on an existing item. It can add attributes to an item modify existing attributes or delete attributes altogether. If the specified key does not exist it adds an item.
4. DeleteItem: This operation removes an item, from the store using its key. If the specified key does not exist no action is taken by this operation.
These operations are essential, for a key value store as they enable insertion updating, deleting and retrieval of items.
Scaling Key-Value Stores
Key-value stores are inherently designed for scalability. They often adopt a distributed architecture, partitioning data across multiple nodes or servers. This design allows the system to manage large data volumes and maintain performance under high loads.
Leaderless Replication
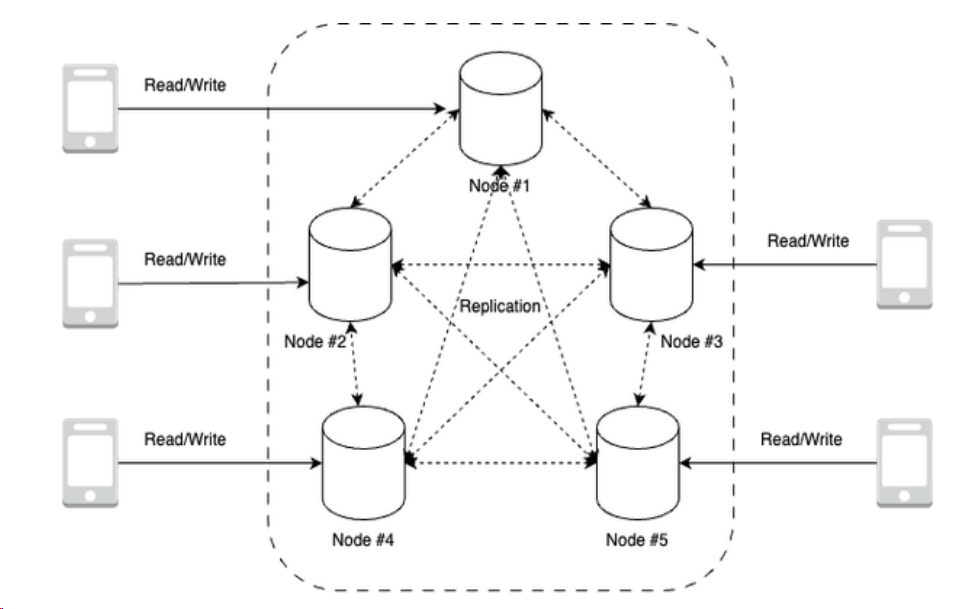
Leaderless replication is a crucial technique in distributed key-value stores, ensuring high availability and fault tolerance. In this model, as shown in Figure 3-2, every node is capable of handling client requests independently, without a designated leader. Data is divided into shards and replicated across nodes using peer-to-peer replication, ensuring redundancy and fault tolerance.
Key aspects of leaderless replication include:
- Quorum Mechanisms: Ensuring a minimum number of nodes agree on any operation for it to be successful.
- Conflict Resolution: Managing data inconsistencies due to concurrent updates or network partitions.
Consistent Hashing
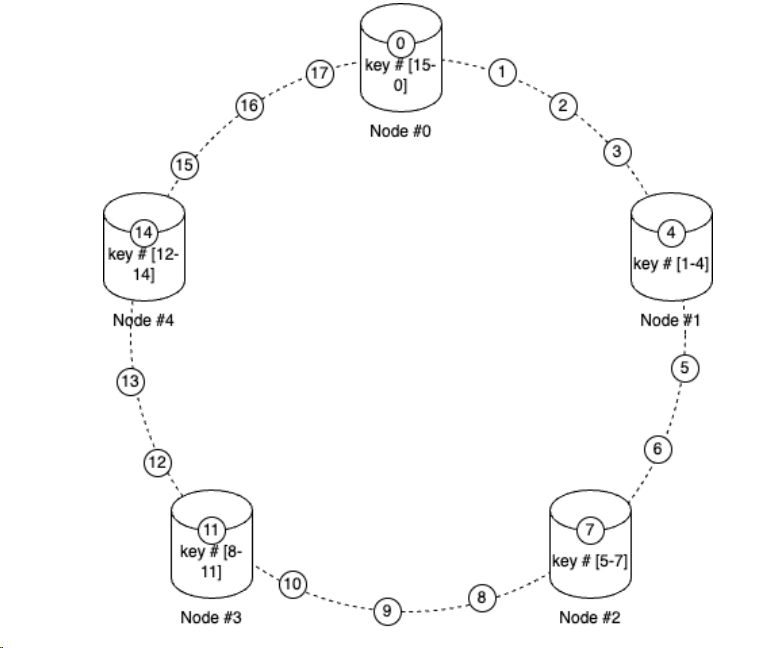
Consistent hashing, depicted in Figure 3-3, is a technique for efficient data distribution in distributed systems. It minimizes the reshuffling of data when nodes are added or removed by mapping data to a ring-like structure where each node and data item has a position. This approach ensures balanced data distribution and minimal data movement, enhancing scalability and availability.
Ensuring High Availability in Key-Value Stores
High availability is vital in distributed key-value stores. Various mechanisms are employed to maintain system responsiveness and reliability:
1. Optimistic Replication: This method allows for continued system operation despite temporary unavailability of some replicas. It assumes successful write operations and resolves inconsistencies through background synchronization.
2. Sloppy Quorum and Last Write Wins (LWW): These techniques manage availability and eventual consistency during network partitions. Sloppy quorum allows operations with a subset of replicas, while LWW resolves conflicts by prioritizing the most recent update based on timestamps.
3. Hinted Handoff: This mechanism deals with temporary unavailability or network issues by storing write operations as hints, which are later delivered to the appropriate replica.
These mechanisms balance availability with consistency, ensuring the key-value store remains resilient and responsive under various conditions.
Conclusion
Key-value stores provide a streamlined approach to data management, excelling in scalability, performance, and availability. The basic operations of GetItem, PutItem, UpdateItem, and DeleteItem enable efficient data manipulation. Scaling is achieved through distributed architectures employing leaderless replication and consistent hashing, ensuring minimal data movement and balanced load distribution.
To maintain high availability, key-value stores leverage techniques like optimistic replication, sloppy quorum with LWW, and hinted handoff, ensuring system resilience and responsiveness. These attributes make key-value stores an ideal choice for applications requiring rapid access to large data volumes and robust scalability, from web applications to large-scale data processing. Understanding these concepts is crucial for leveraging the full potential of key-value databases in today’s data-driven world.
For any software consultant , application development solutions visit our websites.

No comments yet