
In the intricate landscape of distributed computing, understanding and addressing the inherent fallacies is crucial for creating robust, efficient, and scalable software systems. This comprehensive guide delves deep into the common misconceptions identified by L. Peter Deutsch, explores pivotal system design trade-offs, and offers strategies for building resilient distributed systems.
Fallacies of Distributed Computing
Distributed systems, forming the backbone of modern software architecture, are often misunderstood due to prevalent fallacies. Acknowledging these fallacies is the first step toward designing effective systems.
1. Reliable Network
- Fallacy: The assumption that the network is always reliable.
- Reality: Networks are susceptible to various issues, including hardware failures and power outages.
- Countermeasure: Implement robust error handling, retry mechanisms, and failover strategies.
Example in Python: Network Resilience
import requests
from requests.exceptions import HTTPError, ConnectionError
def robust_request(url, retries=3, delay=2):
for attempt in range(retries):
try:
response = requests.get(url)
response.raise_for_status()
return response.json()
except (ConnectionError, HTTPError):
time.sleep(delay)
raise Exception("Network request failed after retries")
Usage
data = robust_request("http://example.com/api")This Python function demonstrates how to handle unreliable networks by implementing retries with exponential backoff.
2. Zero Latency
- Fallacy: Believing latency is non-existent.
- Reality: Latency is an inherent part of networks, limited by physical laws like the speed of light.
- Approach: Utilize edge computing and optimize server locations to reduce latency.
3. Infinite Bandwidth
- Fallacy: Assuming unlimited network bandwidth.
- Reality: Bandwidth constraints lead to network congestion, especially under heavy data load.
- Solution: Opt for efficient data compression and use bandwidth-efficient protocols.
4. Secure Network
- Fallacy: The network is intrinsically secure.
- Reality: Networks are vulnerable to various security threats.
- Defense: Implement end-to-end encryption, use secure protocols, and conduct regular security audits.
5. Fixed Topology
- Fallacy: Network topology is constant.
- Reality: Topology changes due to dynamic conditions like node failures.
- Strategy: Design adaptive systems that can handle topology changes seamlessly.
6. Single Administrator
- Fallacy: There is only one system administrator.
- Reality: Large systems often involve multiple administrative domains.
- Design Principle: Build decoupled, modular systems with distributed management capabilities.
7. Zero Transport Cost
- Fallacy: Data transport incurs no cost.
- Reality: Network infrastructure and data transfer entail significant costs.
- Financial Planning: Include network costs in budget planning and optimization strategies.
8. Homogeneous Network
- Fallacy: Networks are uniform in configuration and protocols.
- Reality: Networks are diverse and complex.
- Implementation: Ensure system interoperability and compatibility across different network configurations.
System Design Trade-offs
Effective system design involves navigating a series of critical trade-offs, balancing various factors like cost, scalability, reliability, and performance.
Time vs. Space
- Challenge: Balancing processing speed with memory usage.
- Example: Using memory caches to store pre-computed results, trading off additional memory usage for faster access.
Latency vs. Throughput
- Challenge: Achieving high throughput can often increase latency.
- Metric Use: Employ percentile metrics (e.g., p50, p90, p99) for latency measurement under different loads.
Performance vs. Scalability
- Challenge: Systems that perform well for individual users might struggle under high load.
- Focus: Design for optimal performance while ensuring scalability to handle increased demands.
Consistency vs. Availability (CAP Theorem)
- Challenge: Balancing data consistency with system availability.
- CAP Theorem: In presence of network partitions, a distributed system can only ensure either consistency or availability.
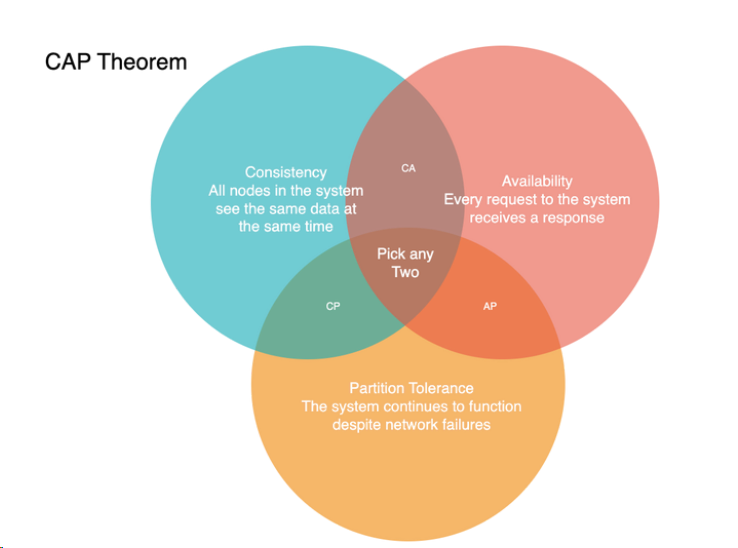
Implications of CAP Theorem
CP (Consistency and Partition Tolerance): In a CP system, during a network partition, operations will not proceed until the partition is resolved, ensuring consistency. However, this comes at the cost of availability—some parts of the system might become inaccessible.
AP (Availability and Partition Tolerance): AP systems prioritize availability over consistency. During partitions, the system continues to operate, but some data reads might be outdated or inconsistent. This is often acceptable in systems where eventual consistency is adequate.
CA (Consistency and Availability without Partition Tolerance): In reality, a CA system is a theoretical concept since partition tolerance is a necessity in distributed systems. A network failure, however small, is inevitable, making partition tolerance a requirement.
Real-world Applications
In practice, the CAP Theorem guides the design and choice of databases and distributed systems. For instance, traditional RDBMS (Relational Database Management Systems) often lean towards CP, offering strong consistency at the expense of availability. NoSQL databases like Cassandra and DynamoDB can be configured for AP, providing high availability with eventual consistency.
Extended with PACELC Theorem
- Additional Layer: Beyond CAP, PACELC introduces a trade-off between latency and consistency during normal operation.
PACELC Theorem
The PACELC Theorem is an extension of the CAP Theorem, which provides a more comprehensive understanding of the trade-offs in distributed systems. Proposed by Daniel Abadi in 2012, the PACELC Theorem states that in distributed databases, if there is a Partition (P), one must choose between Availability and Consistency (as in CAP); Else (when there is no partition), there is a trade-off between Latency and Consistency.
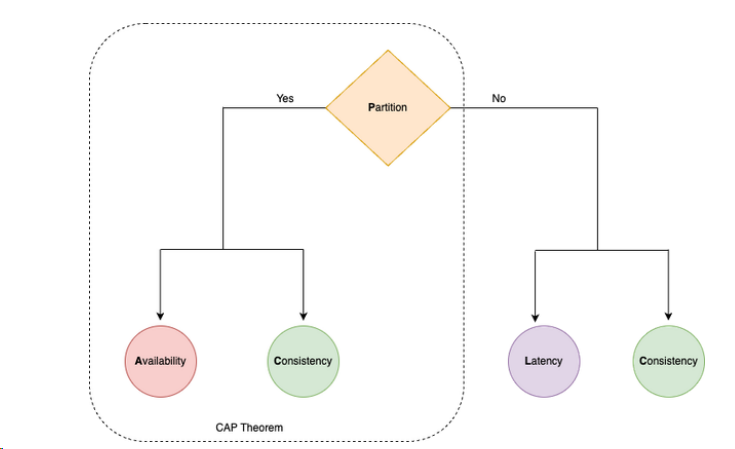
Breaking Down PACELC
- P (Partition): Similar to CAP, PACELC acknowledges that during network partitions, a trade-off between availability and consistency must be made.
- A/C (Availability vs Consistency): This aspect is directly from CAP. If you choose availability, the system will continue to operate despite partitioning but might serve stale or inconsistent data. If consistency is chosen, the system might become partially or entirely unavailable during partitioning to maintain data consistency.
- E (Else - No Partition): PACELC extends the scenario to times when the system is not experiencing a partition. This is the unique addition that PACELC brings to the table.
- L/C (Latency vs Consistency): When the system is not under partition, the trade-off is between latency and consistency. If consistency is paramount, there might be latency due to the overhead of ensuring data is synchronized across nodes. Conversely, if low latency is a priority, the system might sacrifice some degree of consistency.
Implications of PACELC
The PACELC theorem provides a more nuanced view of the trade-offs in distributed systems. It acknowledges that even when the system is operating normally (without partitions), choices still have to be made regarding consistency and latency.
- Consistency-Oriented Systems (CP/EL): These systems prefer consistency over availability during partitions and prioritize consistency over latency during normal operations. They are suitable for applications where data accuracy is critical, like financial services.
- Availability/Latency-Oriented Systems (AP/EL): In such systems, availability is favored during partitions, and low latency is prioritized over consistency when the system is not partitioned. These systems are often used in scenarios where fast response times are more critical than strict consistency, such as in some web applications.
Real-world Applications
PACELC provides a more granular understanding of the behavior of distributed systems, especially NoSQL databases. For instance, Cassandra can be configured to prioritize low latency over strong consistency, making it a good fit for AP/EL scenarios. On the other hand, systems like Google's Spanner, which strive for global consistency, might lean towards CP/EL, accepting higher latencies for cross-region data synchronization.
Code Example: Managing Consistency and Availability in Node.js
const fetchData = async (key) => {
if (detectNetworkPartition()) {
return fetchFromLocalCache(key); // Prioritize availability
} else {
return fetchFromDatabase(key); // Prioritize consistency
}
};This Node.js snippet showcases a decision-making process in a distributed system, balancing consistency and availability based on network conditions.
For any custom software development services , it outsourcing services solutions visit our websites.

No comments yet