
Developing large-scale software systems demands a profound understanding of several key principles: availability, reliability, scalability, and maintainability. This comprehensive guide delves into each of these facets, offering a detailed exploration and practical strategies to engineer resilient and efficient systems design.
Availability: Maximizing Uptime in Software Systems
Availability is the measure of a system's ability to remain operational and responsive. It's a critical metric for any software system, particularly those that serve crucial business functions.
Measuring System Availability is quantified as the percentage of time a system remains functional and accessible.
Availability Formula
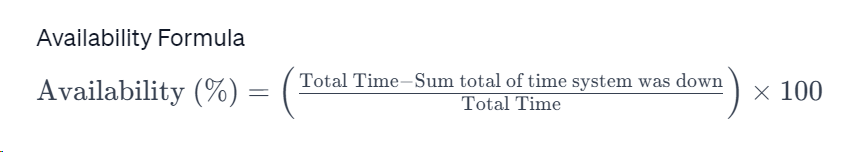
Understanding Availability Tiers
- 90% Availability (One Nine): Up to 36.5 days of downtime per year.
- 99.9% Availability (Three Nines): Approximately 8.76 hours of downtime per year.
- 99.999% Availability (Five Nines): Roughly 5.26 minutes of downtime per year.
Strategies for High Availability
To achieve high availability, systems often incorporate redundant components, backup systems, load balancing, failover mechanisms, and continuous monitoring.
Implementing Load Balancing in Node.js
const http = require('http');
const httpProxy = require('http-proxy');
const servers = ['http://localhost:3001', 'http://localhost:3002'];
let currentIndex = 0;
const proxy = httpProxy.createProxyServer({});
http.createServer((req, res) => {
proxy.web(req, res, { target: servers[currentIndex] });
currentIndex = (currentIndex + 1) % servers.length; // Round-robin algorithm
}).listen(3000);This example demonstrates a basic load balancer in Node.js, using a round-robin strategy to distribute requests across servers.
Reliability: Ensuring System Consistency
Reliability refers to the system's ability to perform its intended function consistently over time.
Reliability Metrics
- Mean Time Between Failures (MTBF): Average operational time between failures.
- Mean Time To Repair (MTTR): Average time required to repair a system failure.
Reliability Equation
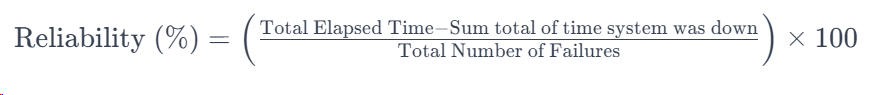
A high MTBF and low MTTR indicate a reliable system capable of consistent performance and quick recovery.
Scalability: Adapting to Demand
Scalability is the capability of a system to handle increased workload without performance degradation.
Vertical vs Horizontal Scaling
- Vertical Scaling: Enhancing the capacity of an existing server.
- Horizontal Scaling: Adding more servers to distribute the workload.
Cloud-Based Auto-Scaling Example
const cloudService = new CloudServiceProvider();
cloudService.setupAutoScaling({
minimumInstances: 2,
maximumInstances: 10,
cpuThreshold: 75, // Scale up when CPU usage exceeds 75%
});This pseudo-code for a cloud-based auto-scaling setup adjusts the number of active server instances based on current CPU usage.
Maintainability: Simplifying System Adaptation
Maintainability involves the ease with which a system can be modified, updated, or extended.
Aspects of Maintainability
- Operability: The system's ability to operate smoothly and recover quickly from faults.
- Lucidity: The clarity and simplicity of the system, facilitating easy understanding and debugging.
- Modifiability: The capacity to modify and extend the system without major overhauls.
Example: Modular Design in Node.js
// userModule.js
module.exports = {
createUser: () => { /* …* / },
deleteUser: () => { /* ... */ }
};
// main.js
const userModule = require('./userModule');
userModule.createUser();This modular approach in Node.js demonstrates how separating functionalities into modules enhances system maintainability.
Fault Tolerance: Enhancing System Resilience
Fault tolerance is the attribute of a system to continue functioning in the event of partial system failures.
Building Fault-Tolerant Systems
Key strategies include replication and checkpointing to ensure data safety and service continuity.
Replication Patterns
- Multi-Leader Replication: Multiple systems operate in parallel, handling read and write operations.
- Single Leader Replication: One system (leader) handles write operations, while others (followers) replicate the data.
Checkpointing for Data Safety
Checkpointing involves periodically saving the state of a system to facilitate recovery after failures.
Example: Basic Checkpointing Mechanism
const fs = require('fs');
function saveCheckpoint(data) {
fs.writeFile('checkpoint.dat', JSON.stringify(data), err => {
if (err) throw err;
});
}This function periodically saves the system state to a file, allowing for data recovery in the event of a system crash.
Designing a system often involves balancing reliability, availability, and scalability. For instance, a highly available system might need to sacrifice some aspects of scalability.
Crafting a high-performing software system necessitates a nuanced understanding of availability, reliability, scalability, and maintainability. By judiciously applying these principles, developers can construct systems that are not only efficient and robust but also prepared to evolve with future requirements. Balancing these aspects, while challenging, is essential for creating systems that deliver consistent, reliable performance and can scale gracefully in response to increasing demands.
For any software consultant , application development solutions visit our websites

No comments yet