
In the ever-evolving world of data management, the need for efficient and scalable database solutions has never been greater. Sharding emerges as a critical technique in this context, especially for handling large databases. But what exactly is sharding, and how does it function?
Sharding is essentially the process of distributing a database across multiple servers. Each server holds a part of the total data, allowing queries to be spread across these servers. This method is particularly useful for scaling up databases that have grown beyond the capacity of a single server. For instance, consider a customer database that expands alongside the customer base. As more customers are added, more shards (or partitions) are introduced to the cluster to manage this increased load effectively.
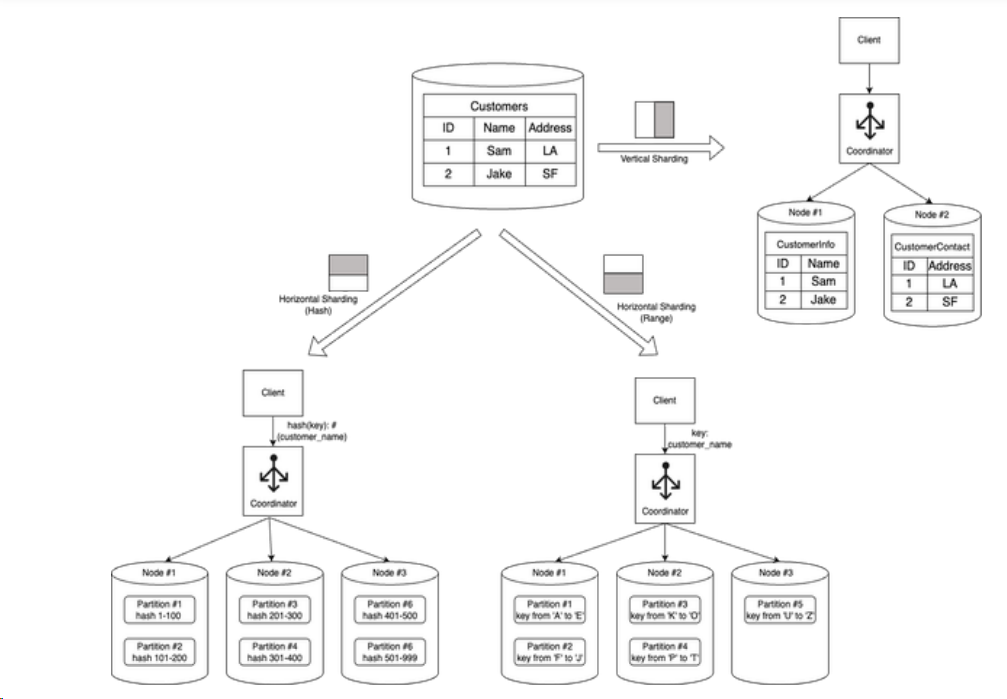
Types of Sharding and Their Approaches
Sharding can be categorized into two main types: vertical and horizontal. Each comes with unique approaches for partitioning the data.
1. Vertical Sharding: This involves dividing a database into smaller parts based on specific tables or columns. It's akin to slicing a cake vertically, where each slice represents a subset of the entire data structure.
2. Horizontal Sharding: This type of sharding splits the database row-wise. It's like cutting a cake horizontally, where each layer signifies a fraction of the total data. Within horizontal sharding, there are several methods:
- Hash-Based Sharding: This approach uses a hash function to distribute data across various shards.
- Range-Based Sharding: Data is partitioned according to specific ranges, like dates or numerical values.
- Round-Robin Sharding: Data is distributed evenly across all shards in a cyclic manner.
Advantages of Sharding
Sharding offers numerous benefits, similar to those of database federation. These include reduced traffic for reads and writes, lower replication needs, better cache utilization, and smaller indexes which lead to faster query performance. It also eliminates the necessity of a central master for write serialization, allowing for parallel writes and increased throughput.
However, sharding isn't without its challenges. It can complicate application logic, potentially lead to unbalanced data distribution, and make data rebalancing a complex task. Joining data across shards becomes more difficult, and the system as a whole becomes more complex and demanding in terms of hardware requirements.
Replication in Distributed Databases
Moving to another vital aspect of distributed databases, replication refers to the process of duplicating data from one database server to another. Each node that stores a copy is known as a replica. Replication is a key feature in distributed databases, offering high availability, load distribution, reduced latency, disaster recovery, and improved scalability and performance.
Types of Replication
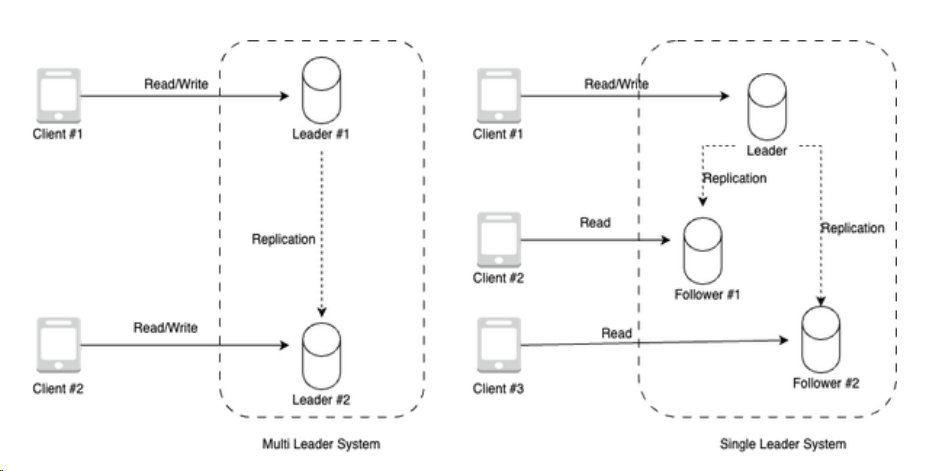
Two primary replication methods are prevalent in relational database management systems (RDBMS):
- Single-leader Replication: In this model, one server acts as the leader, handling all write operations, while the followers manage read operations.
- Multi-leader Replication: Each server in this setup can perform both read and write operations. Changes on one server are replicated across others.
Additionally, replication can be achieved through full replication, snapshot-based replication, transactional replication, or key-based incremental replication. These can be executed synchronously or asynchronously.
Advantages of Synchronous Replication
In synchronous replication, data from a leader replica is replicated to follower replicas in real-time. This approach ensures consistent writes, immediate failover, data durability, and consistency in read operations.
1. Consistent Writes: A write is considered successful only when confirmed by both the leader and the follower replicas.
2. Immediate Failover: In case of a leader replica crash, any synchronous replica can be immediately promoted as the new leader.
3. Data Durability: Data is stored across multiple replicas, ensuring safety and recoverability.
4. Consistency in Read Operations: Synchronous replicas provide the most recent data, enabling efficient load balancing and handling of read-intensive workloads.
Sharding and replication are pivotal in the architecture of distributed databases. Sharding aids in managing large-scale data distribution, while replication ensures data availability, resilience, and performance. Understanding these concepts is crucial for database administrators, developers, and anyone involved in data management and architecture design. As databases continue to grow in size and complexity, the efficient implementation of sharding and replication will remain a cornerstone of scalable, robust, and high-performing data management strategies.
Asynchronous Replication in Scaling Distributed Databases
Asynchronous replication is a method of replicating data from a primary (leader) replica to one or more secondary (asynchronous) replicas. This replication model has distinct characteristics and considerations:
1. Near Real-Time Updates: Asynchronous replicas apply changes from the leader replica almost in real-time. However, there's a potential delay, meaning that the replicas might not always be immediately up-to-date with the leader’s latest changes. This temporal inconsistency is a crucial factor to consider in systems where the most current data is vital.
2. Data Lag and Potential Staleness: The nature of asynchronous replication inevitably leads to a lag between the leader and the asynchronous replicas. The degree of this lag varies based on network conditions, system load, and the volume of data changes. This lag can result in the replicas not reflecting the most recent data state, which is a significant consideration for applications needing the latest information.
3. Risk of Data Loss: In the event of a leader replica crash, promoting an asynchronous replica to the leader role carries the risk of data loss. This risk arises because the asynchronous replica may not have received or applied all the changes from the original leader, leading to potential data inconsistencies.
4. Scalability and Performance: Asynchronous replication is often chosen for systems that prioritize scalability and performance over strict data consistency. This approach allows high write throughput and can support large-scale systems by distributing workload efficiently.
Balancing Benefits and Risks
Asynchronous replication offers scalability and performance advantages but also introduces the possibility of data lag and potential staleness. This trade-off requires careful planning and monitoring:
- High Availability and Load Distribution: Asynchronous replication enhances system availability and distributes loads effectively across various nodes, making it ideal for systems with high read traffic.
- Reduced Latency and Disaster Recovery: By replicating data across geographically distributed nodes, asynchronous replication reduces latency and serves as a backbone for disaster recovery strategies.
- Scalability and Enhanced Performance: This replication method plays a critical role in scaling distributed databases. It allows for horizontal scaling, which is essential for handling increasing data volumes and traffic.
Best Practices for Managing Asynchronous Replication
1. Monitoring Replication Lag: Regularly monitoring the lag between the leader and asynchronous replicas is crucial. This monitoring helps in understanding the current state of data consistency and readiness for potential leader promotion.
2. Fallback Mechanisms: Implementing robust fallback and recovery mechanisms ensures data integrity and minimizes the impact of data inconsistencies. This includes having strategies for data backup and recovery in case of replica failures.
3. Careful Replica Promotion: Before promoting an asynchronous replica to a leader role, it’s critical to ensure that it has sufficiently caught up with the leader’s data state. This minimizes the risk of data loss and inconsistencies.
Asynchronous replication is a vital component in the architecture of distributed databases, especially when it comes to scaling and performance optimization. While it offers numerous advantages like high availability, load distribution, and scalability, it also brings challenges such as data lag and the risk of data loss. By understanding these dynamics and implementing best practices like thorough monitoring and robust fallback mechanisms, organizations can leverage asynchronous replication effectively. This approach ensures a balance between performance, scalability, and data integrity in distributed database environments. As the demand for handling larger data volumes and traffic increases, mastering asynchronous replication will continue to be an essential skill for database administrators and architects.
For any custom software development services , it outsourcing services solutions visit our websites.

No comments yet