
The “onosecond” is the second after you make a terrible mistake. The second when you realise what you just did and that there’s nothing you can do about it, the second when all the now-inevitable consequences flash through your mind. It is the second after you send a text message to the wrong person, after you delete the wrong file, after you spill the secret that you thought they already knew. The “onosecond” is that stomach-dropping, breath-stopping moment when all you can do is say “oh, no”. This is the story of the worst typo I ever made.
I was maybe 18 or 19, in charge of converting an old web site to a new and faster platform. A half-dozen volunteers had spent days transferring all the articles over, copying them from the old site, updating them, and then saving them in their new place. It had been a lot of effort, but everything was pretty much sorted now. There was one thing I needed to do: a search-and-replace across all those pages of content. And I was wise to the mistake that people usually make there: it’s called the clbuttic mistake, where someone wants to censor the word “ass” and the search-and-replace gets a little bit more enthusiastic than they thought it would.  This problem: much simpler. The volunteers had just written the articles in plain text, and I needed to add some simple formatting. Anywhere there were three dashes, I just needed to replace that with a tag for a horizontal line. There’s no way that search-and-replace could go wrong. Right?
This problem: much simpler. The volunteers had just written the articles in plain text, and I needed to add some simple formatting. Anywhere there were three dashes, I just needed to replace that with a tag for a horizontal line. There’s no way that search-and-replace could go wrong. Right?
This was the mid-2000s, so the site wasn’t anything fancy: it was a standard SQL database. SQL is Structured Query Language: it’s an international standard for sending commands to basic databases, and it’s still used today. I hadn’t bothered to set up any tools to help me along with it. I was the only one working on the site, so I was just using the command line. Which meant that with a single instruction, I could change every record in the live database, every single page, at once.
Working on a live database is a bit like working with a live mains electricity cable. Sure, it’s physically possible, it’d make things quicker, and there are very, very rare occasions where it might actually be the only option. But in general, if you’re working on mains electricity, you turn the power off first. And if you’re working on a database, you don’t work on the live version.
I was working on the live version. Because I was young, and careless, and besides, the difficult part was over, right? After all that conversion work, and it was a lot of work, I just had to issue a few final commands. Update the list of articles, and set the content field to itself, just with the dashes replaced with the tag. So I typed in the command, hit enter, and... 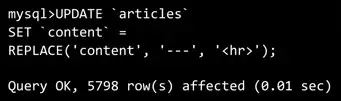 Reading 5,000 pages, doing a search and replace across all that text, and putting it all back into the database, should have taken a bit more than one-hundredth of a second. I didn’t know what had happened yet, but I knew something had gone wrong.
Reading 5,000 pages, doing a search and replace across all that text, and putting it all back into the database, should have taken a bit more than one-hundredth of a second. I didn’t know what had happened yet, but I knew something had gone wrong.
Hold that thought. In the history of computer science, the undo command was invented independently several times. In the 1970s, programmers at the Xerox PARC research centre were the first to assign it to that easy-to-reach keyboard shortcut of Ctrl-Z. Or "Zed". Their work there later, uh, inspired many features that ended up in Apple computers. And most of the time undo is linear: there is an ordered list of commands that we’ve issued, and we can undo -- or redo -- our way back and forth through that list.
The most basic way to implement that is to store the exact state of the document after every single command, or even after each keystroke, and just roll back to that. It’s memory-intensive, and there are a lot of ways to optimise it, but that’ll work. It’s also an easy mental model for users to deal with: you just step back and forth in time. But if you go back in time, and then make a small change, you won’t be able to redo your way back forwards. Like a time traveller in science fiction, you’ve broken the future.
So if you do want to recover something you deleted and bring it forward in time with you, you’ll have to be really careful not to accidentally hit the wrong key while you’re back there.
Plenty of folks have tried to create ‘undo trees’: so if you do back and change history, it just creates a new timeline, and you can move around the timelines however you want.
There are some text editors which’ll do that for you, and even visualise all the branches. But it’s a complicated thing to keep in your head, and it’s never found mainstream appeal.
There are source control systems that work the same way, like Git: every time you save your file and ‘commit’ it, that copy is available forever. Multiple people can work on files at the same time, make changes in different ‘branches’, and everything just gets merged back together afterwards. It’s incredibly useful for any software development project.
But trying to do that for every keystroke, rather than every saved version of a file, is a bit much. Saving keystrokes works in memory, which is fast; saving files works on disk, which is comparatively slow.
Microsoft Word used to have a Fast Save feature, where if you’d updated a few things in the document, it didn’t actually save the whole thing all over again: it just appended those changes on the end, so you didn’t have to wait five or ten seconds every time you hit Control-S to save on an old 90s computer. It turned out that leaving stuff in files that users thought they’d deleted was a massive privacy and security risk, and that got turned off in 2003.
That model: quick undo for live work in memory, and a slower save to disk when you’re done with a task, is still used in a lot of places… although it is slowly changing. If you write text in Google Docs or other cloud-based platforms, then your keystrokes are constantly saved and synchronised. You never actually have to hit ‘save’. Which means that depending on which app you’re working in, you have to change your mental model of how your work is saved. And sometimes you don’t want to save every single keystroke and command.
If you got frustrated at your boss, typed some… colourful comments into your code, and then deleted them, they probably shouldn’t be stored forever. Or maybe you pasted a password or security key or credit card number into the wrong file, and you definitely don’t want Derek the intern to have access to that forevermore.
Anyway: the point is, there are all sorts of systems, big and small, designed to allow you to undo and redo. In MySQL, the language I was using for that database, they had “transactions”. And you could type the command START TRANSACTION. Any edits you made would be accepted, but they wouldn’t be actually, properly, definitely, irrevocably saved until you typed COMMIT. If you screwed up, you typed ROLLBACK, and the database just forgot those commands had ever been sent in. Which is great, right? Because everyone makes typos.
Can you spot it? 'Cos it’s really subtle. The database had gone into the ‘articles’ table, and for every single article, it had changed the ‘content’ field. Those words: ‘articles’ and ‘content’, they’re surrounded by backticks, that odd character to the left of the 1 on most keyboards. Backticks mean “this is the name of a table or field, “I’m referring to something in the database”. That’s all fine.
Then it looked at the “replace” command. And I’d told it that for each article, it should pull the content, and replace the dashes with the tag. Everything’s in the right order there, I remember checking that I’d got it all the right way round. Except that’s where I messed up.  They’re not backticks. They’re apostrophes. And apostrophes mean ‘this is a literal string of text’. Not a name. So, as I had ordered, the database promptly took the literal word “content”,
They’re not backticks. They’re apostrophes. And apostrophes mean ‘this is a literal string of text’. Not a name. So, as I had ordered, the database promptly took the literal word “content”, content, looked through it for dashes, found none, replaced nothing, and then put that word ‘content’ into the content field. For 5,000 articles. And I looked at the web site. All the volunteers’ hard work. 5,000 pages. Every single page, just replaced with the word “content”.
Genuinely, my pulse rate is rising a little as I think about that. I was nearly physically sick. Because I knew what was going to happen next. Because that typo is an entirely reasonable mistake to make. There’s nothing wrong with screwing up like that. Everyone makes errors like that, all the time. And we hit Control-Z. Or we click the ‘Undo’ button. In Gmail, we hit ‘undo send’, at least for the 30 seconds before it actually does send the message. And if you happen to be enough of a prat to be working on a live SQL database, you type in ROLLBACK, but hadn’t told it to start a transaction.
And there are all sorts of words I could use to describe the idea of working on a live database without even a transaction as a safety net. Ridiculous. Asinine. Unthinking. But the one I think is most accurate is: negligent. The only reason that typo was the worst I’ve ever made was because of all the poor decisions that led up to it. Working on a live database. Thinking I couldn’t screw up one simple command. Not having any sort of backup! Days of work by volunteers and at no point during that had I thought, you know what, maybe we should get a copy of that somewhere else just in case? Like, that should have been backed up daily, or hourly.
The root cause of all that, of all the days afterwards where I had to apologise to so many people, the root cause wasn’t one typo. It was the overconfidence and negligence that meant I didn’t have any way to undo my mistakes. It’s the sort of lesson you only learn once. Programmers and anyone who works with software, we have this magical ability to undo. No professional that works with physical, real-world things has that option.
So if you don’t have a backup of your code, or your thesis, or the photos on your phone, or your database, get a backup. Don’t put it off for the future. And if you do have one ready: check it works. Because you don’t want to have the same feeling of: oh, no.

No comments yet