
Previous: Part 9 - Using the Sequencing APIs
Over the last few parts, we haven't done much machine learning. Instead, we looked at how you can preprocess text data to get it ready for training machine learning models. In this part, you're going to put that knowledge to use in training a text classifier, a model, which, when given a piece of text, will understand the contents of that text.
You'll be working with the Sarcasm in News Headlines data set by Rishabh Misra, which is available on his website here. This is a really fun data set, which collects news headlines from normal news sources, as well as some more comedic ones from spoof news sites.
The data set is a JSON file with three columns. The is_sarcastic one is 1 if the record is sarcastic. Otherwise, it's 0. The headline is the headline of the article, and the article_link is a URL to the text of the article. We're just going to deal with the headlines here. So we have a super easy data set to work with. The headline is our feature, and the is_sarcastic is our label.
The data in JSON looks a bit like this.
{
"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5",
"headline": "former versace store clerk sues over secret 'black code' for minority shoppers",
"is_sarcastic": 0
}
Each entry is a JSON field with the name-value pairs showing the column and associated data.
Here's the code to load it in Python when it's structured like that.
import json
with open("sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
urls = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link'])
I'll go through this piece by piece. First, we'll import json so that we can use the json parsers in Python. Then we'll open the sarcasm.json file. Using json.load(), we can load and parse the entire thing. I'll initialize arrays for the sentences, labels, and URLs. And I can now simply iterate through the datastore. And, for each item, I can append its headline, the sarcasm label, and URL to the appropriate array.
And that's it for loading the data. In previous parts, you may recall that we had hard-coded sentences into an array of strings. We now have exactly the same data structure for the headline sentences, despite that there are now over 25,000 of them. So, for the next code, despite us using this real data set, it will look very familiar. So let's dive in.
So here's the code to tokenize and sequence the sarcasm data set.
from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences tokenizer = Tokenizer(oov_token="") tokenizer.fit_on_texts(sentences) word_index = tokenizer.word_index
print(len(word_index)) print(word_index)
sequences = tokenizer.texts_to_sequences(sentences) padded = pad_sequences(sequences, padding='post')
print(padded[0]) print(padded.shape)
We create a tokenizer and fit it on the sentences. In this case, the sentences are the large array of 25,000-plus sentences that we read from the sarcasm data set. We can use the tokenizer to show us the word_index so we can see what words it learned from the data set. And here's an example of some of the words.
... 'blowing': 4064, 'packed': 4065, 'deficit': 4066, 'essential': 4067, 'explaining': 4068, 'pollution': 4069, 'braces': 4070, 'protester': 4071, 'uncle': 4072 ...
Remember from earlier that the words with the lower number tokens are the ones that are more common, and the ones with the higher numbers, was less commonly used in the data set. So, of all of the words here, hurting is the one that was found most often.
We can now turn all of our sentences into sequences where, instead of words, we have the tokens representing those words. We'll pad them post, which means that all of the sentences will be the length of whatever the longest one is. And anything shorter than that will be padded with zeros at the end of the sentences in order to keep them all the same length. If we want to inspect them, we can then print out one of them, and we can print out the shape of the entire padded data structure. You'll see output like this.
[ 308 15115 679 3337 2298 48 382 2576 15116 6 2577 8434
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
(26709, 40)
This is the first sentence in our corpus after tokenizing and padding. It's a shorter sentence. So it ends with a bunch of zeros. And this is the shape of the data structure for the padding. This tells us that we have 26,709 padded sentences, and each of these is 40 values long.
With just a few lines of code, you've loaded the data from sarcasm into sentence arrays, tokenized, and padded them.
First, in the code, you'll see a number of commonly used variables. Each of these will be used throughout the code. You've seen many of them so far, but others, like the embedding dimension, will be clear later. The training_size of 20,000 will be used next.
vocab_size = 10000 embedding_dim = 16 max_length = 100 trunc_type='post' padding_type='post' oov_tok = "" training_size = 20000
We have a corpus of many thousands of sentences and labels. And, moments ago, we specified 20,000 as the training_size. So that many sentences and labels will be the training set. And we'll hold back the other 6,000 or so as a validation set.
So our training_sentences will be the complete corpus from 0 to the training_size. And our testing_sentences will be from the training_size to the end of the set. We can do similar with the labels. The training will be the first batch, and the testing will be the last ones.
training_sentences = sentences[0:training_size] testing_sentences = sentences[training_size:] training_labels = labels[0:training_size] testing_labels = labels[training_size:]
As we've split the data into training and testing sets, we should do the same for the padded sets, instead of having that one large master one that we had earlier on.
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok) tokenizer.fit_on_texts(training_sentences) word_index = tokenizer.word_index training_sequences = tokenizer.texts_to_sequences(training_sentences) training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) testing_sequences = tokenizer.texts_to_sequences(testing_sentences) testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
First, we'll create a tokenizer, and we'll specify the number of words that we want and what the out-of-vocabulary token should be. We'll fit the tokenizer to just the training_sentence corpus. This will help us accurately reflect any real-world usage. Our testing_sentences can be tested against the vocab that was learned from the training set. Now we can create a set of training_sequences from just the training_sentences. And we can pad these to get a set of padded training sentences. And then we can just do the same thing for the testing_sentences and for all the labels.
So before we can train a model with this, let's take a look at the concept of embeddings, which help us turn the sentiment of a word into a number in much the same way as we tokenized words earlier. In this case, an embedding is a vector pointing in a direction, and we can use those directions to establish meanings in words. I know this is all very vague. So let me explain it visually.
For example, consider the words bad and good. Now we know they have opposite meanings. So we could draw them as arrows pointing in opposite directions. We could then describe the word meh as being sort of bad, but not really that bad. So it might be an arrow like this.
We could then describe the word meh as being sort of bad, but not really that bad. So it might be an arrow like this.  And then the phrase not bad, it's not as strong as good, but it's more or less in the same direction as good. So we could draw it with an arrow like this.
And then the phrase not bad, it's not as strong as good, but it's more or less in the same direction as good. So we could draw it with an arrow like this. If we then plot these on a chart, we could then get coordinates for these arrows. These coordinates could then be seen as embeddings for the sentiment of those words.
If we then plot these on a chart, we could then get coordinates for these arrows. These coordinates could then be seen as embeddings for the sentiment of those words. 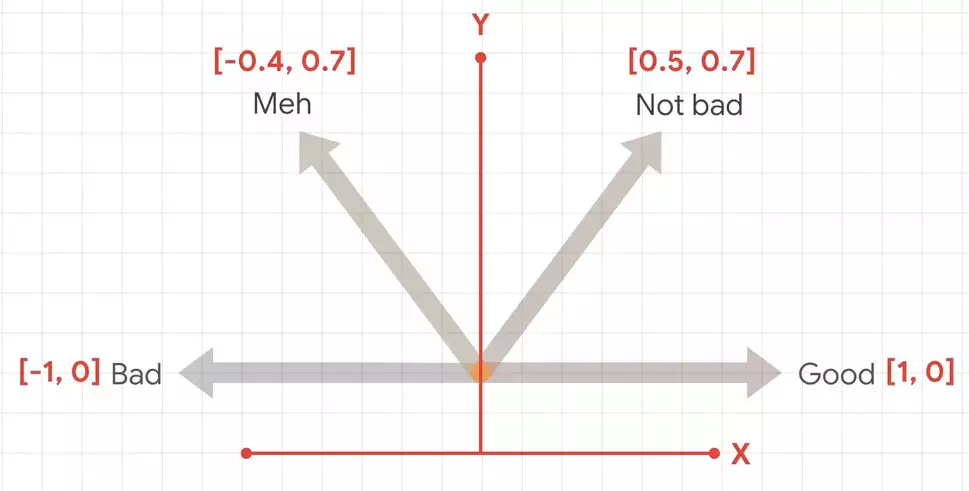 There's no absolute meaning, but, relative to each other, we can establish sentiment.
There's no absolute meaning, but, relative to each other, we can establish sentiment.
To do this in code, we can simply use a Keras layer called an Embedding.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
Our Embedding should be defined as a vector for every word. So we're going to take vocab-sized words and then specify how many dimensions we want the arrow direction to use. In this case, it's 16 that we created earlier. So the Embedding layer will learn 10,016 dimension vectors where the direction of the vector establishes the sentiment of the word. By matching the words to the labels, it'll have a direction that it can then start learning from.
Once we've defined the model, we can then train it like this.
num_epochs = 30 history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)
We simply specify the training_padded features and labels, as well as the validation ones.
Now you can try it for yourself. Here's the URL.
Hopefully that was an interesting exploration for you into the beginnings of NLP with TensorFlow. And that brings us to the end of this 10-part series on foundations of machine learning. I hope you've enjoyed these series, and I hope you've been able to learn from them.

No comments yet